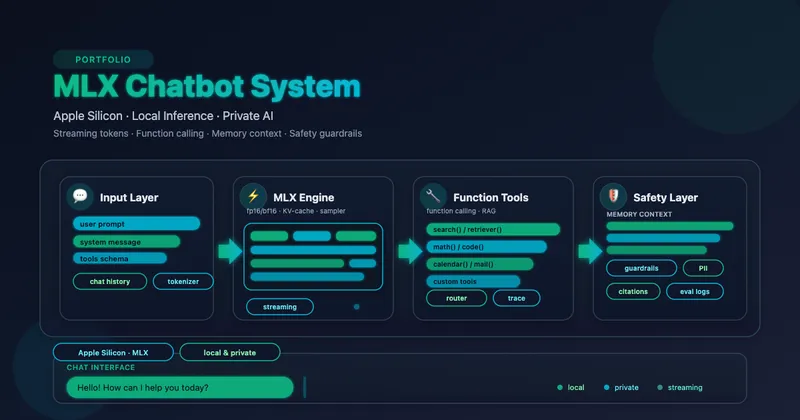
RAG System: A Case Study in Local-First Document Q&A
Check the repo: RAG, Llama3, and Elasticsearch project repository
Problem Statement
The Challenge
Organizations accumulate vast amounts of unstructured text data—customer support logs, internal documentation, conversation transcripts—but extracting actionable insights from these documents remains painful. Traditional keyword search fails to understand semantic meaning, returning irrelevant results when users phrase questions differently than the source text.
I wanted to explore how modern LLMs could transform document retrieval. The goal was simple: build a system where users could ask natural language questions about their documents and receive accurate, contextual answers—all running locally without sending data to external APIs.
Why This Matters
The privacy implications of sending proprietary documents to cloud LLM providers concern many organizations. Customer conversations, internal processes, and business-sensitive information shouldn’t leave controlled environments. A local-first RAG system addresses this by keeping both the data and the inference entirely on-premise.
Beyond privacy, I wanted to understand the RAG pipeline deeply. Frameworks like LangChain and LlamaIndex abstract away complexity, but understanding what happens under the hood—chunking strategies, embedding generation, vector similarity search, prompt construction—is essential for debugging production systems and making informed architectural decisions.
Constraints
- Fully local deployment: No external API calls for embeddings or generation
- Reasonable hardware: Must run on consumer-grade machines (no GPU clusters)
- JSON document support: Focus on structured conversation data initially
- Interactive interface: Users should see results in real-time via a web UI
Technical Approach
System Architecture
The system follows a classic RAG pattern with three distinct phases: ingestion, retrieval, and generation.
Key Design Decisions
1. Elasticsearch Over Specialized Vector DBs
I chose Elasticsearch over purpose-built vector databases like Pinecone, Weaviate, or Qdrant for several reasons:
| Consideration | Elasticsearch | Specialized Vector DBs |
|---|---|---|
| Hybrid search | Native BM25 + vector | Often vector-only |
| Operational maturity | Battle-tested at scale | Newer, less proven |
| Local deployment | Docker single-node easy | Varies by provider |
| Existing tooling | Kibana, monitoring built-in | Often limited |
For a production system, I’d want the option to combine semantic search with traditional keyword matching. Elasticsearch’s dense vector fields with HNSW indexing provide competitive retrieval quality while maintaining flexibility.
2. LlamaIndex as the Orchestration Layer
Rather than building retrieval pipelines from scratch, LlamaIndex provides:
- Standardized abstractions:
Document,Node,Indexconcepts map cleanly to RAG workflows - Pluggable components: Swap embedding models, vector stores, or LLMs without rewriting logic
- Built-in chunking:
SentenceSplitterhandles text segmentation intelligently
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.ollama import OllamaEmbedding
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=350, chunk_overlap=50),
OllamaEmbedding("llama3")
],
vector_store=es_vector_store
)
The IngestionPipeline abstracts the transform-embed-store workflow into a single declarative configuration.
3. Ollama for Local Model Serving
Ollama dramatically simplifies running LLMs locally. A single command downloads and serves models:
ollama run llama3
This exposes a local API compatible with OpenAI’s format, making it trivial to integrate with LlamaIndex:
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
# Same model for embeddings and generation
local_llm = Ollama(model="llama3")
embed_model = OllamaEmbedding("llama3")
4. Chunking Strategy
The chunking configuration significantly impacts retrieval quality:
SentenceSplitter(chunk_size=350, chunk_overlap=50)
- chunk_size=350: Small enough to maintain semantic coherence, large enough to preserve context
- chunk_overlap=50: Prevents information loss at chunk boundaries
For conversation data, this typically yields 1-3 chunks per conversation, preserving the dialogue flow while enabling fine-grained retrieval.
Implementation Deep Dive
Document Ingestion
The ingestion module transforms raw JSON into embedded vectors stored in Elasticsearch:
from elasticsearch import AsyncElasticsearch
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from llama_index.core import Document
# Elasticsearch connection
es_client = AsyncElasticsearch("http://localhost:9200")
es_vector_store = ElasticsearchStore(
index_name="calls",
vector_field='conversation_vector',
text_field='conversation',
es_client=es_client
)
def get_documents_from_json(json_data) -> list:
"""Convert JSON records to LlamaIndex Documents."""
return [
Document(
text=item["conversation"],
metadata={"conversation_id": item["conversation_id"]}
)
for item in json_data
]
def ingest_documents(documents):
"""Run the ingestion pipeline."""
ollama_embedding = OllamaEmbedding("llama3")
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=350, chunk_overlap=50),
ollama_embedding
],
vector_store=es_vector_store
)
pipeline.run(documents=documents)
Query Engine Setup
The query engine combines retrieval and generation:
from llama_index.core import VectorStoreIndex, QueryBundle, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
def setup_query_engine(model_name="llama3"):
"""Configure the RAG query engine."""
local_llm = Ollama(model=model_name)
Settings.embed_model = OllamaEmbedding(model_name)
# Build index from existing vector store
index = VectorStoreIndex.from_vector_store(es_vector_store)
# Return query engine with top-10 retrieval
return index.as_query_engine(local_llm, similarity_top_k=10)
def execute_query(query_engine, query_text):
"""Execute a query and return the response."""
bundle = QueryBundle(
query_text,
embedding=Settings.embed_model.get_query_embedding(query_text)
)
return query_engine.query(bundle)
Streamlit Interface
The UI handles document upload and query execution:
async def check_embeddings():
"""Verify if documents are already indexed."""
try:
index_exists = await es_client.indices.exists(index="calls")
if index_exists:
doc_count = await es_client.count(
index="calls",
body={"query": {"exists": {"field": "conversation_vector"}}}
)
return doc_count['count'] > 0
return False
except Exception as e:
st.error(f"Elasticsearch connection failed: {e}")
return False
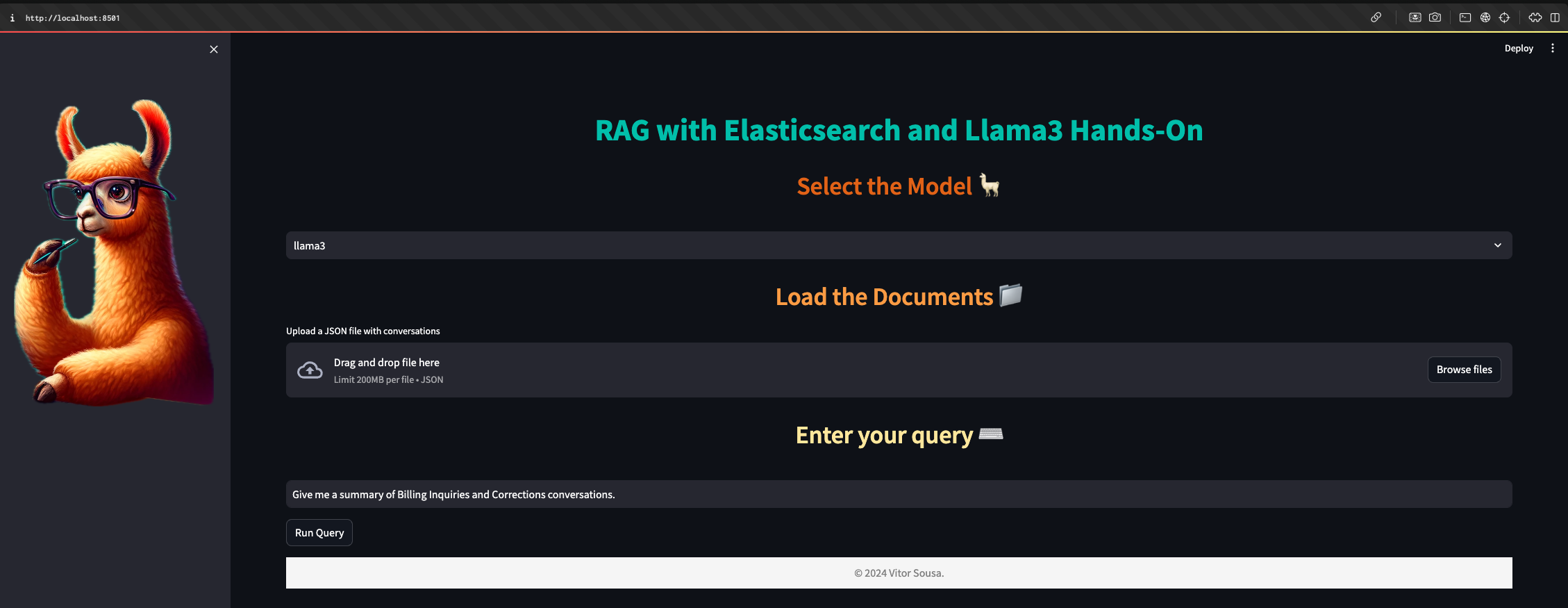
Results & Metrics
Qualitative Performance
The system successfully answers semantic queries over conversation data:
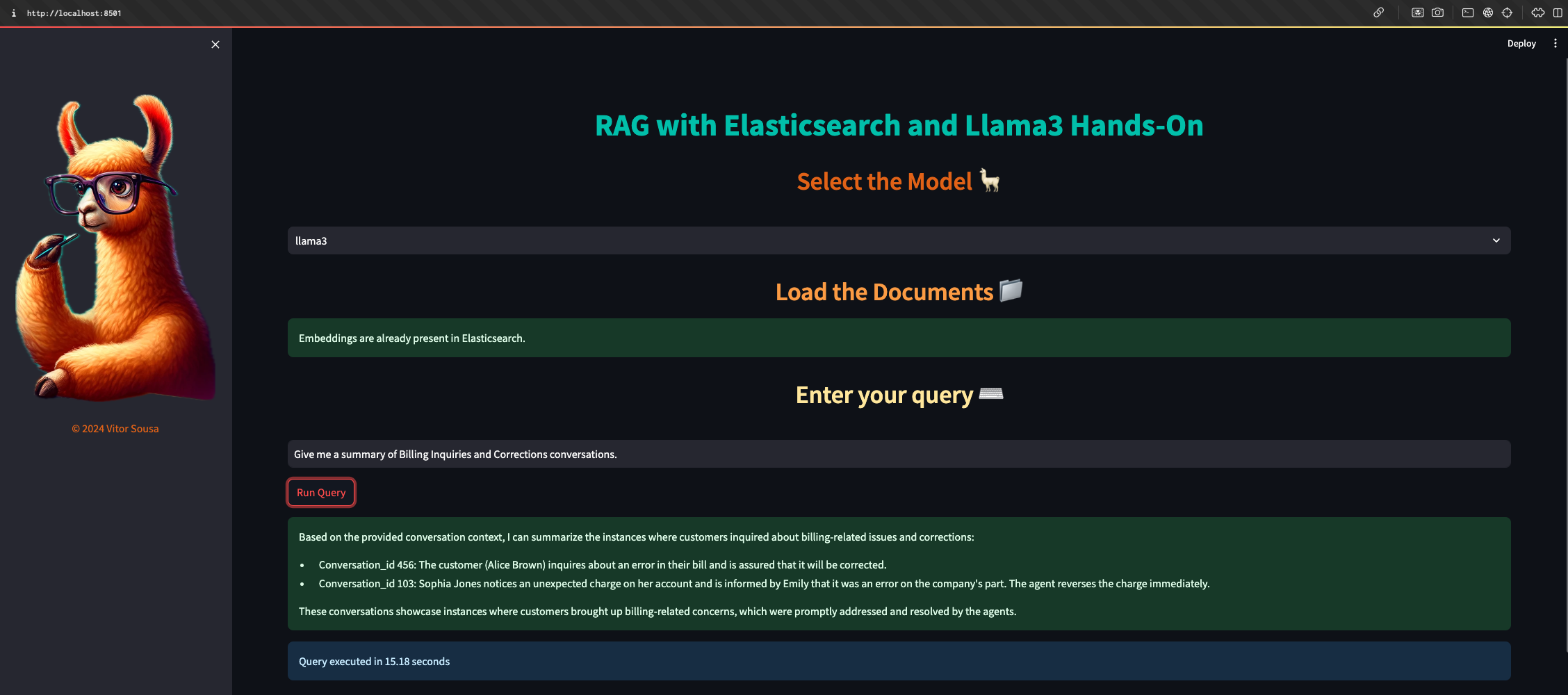
Example query: “Give me a summary of Billing Inquiries and Corrections conversations.”
The system retrieves relevant conversations and synthesizes a coherent summary, demonstrating:
- Semantic understanding (not just keyword matching)
- Cross-document synthesis
- Natural language response generation
Observed Characteristics
| Metric | Observation |
|---|---|
| Ingestion speed | ~2-3 seconds per document (CPU-only, Llama3 8B) |
| Query latency | 5-15 seconds end-to-end (retrieval + generation) |
| Memory usage | ~8GB for Ollama + Elasticsearch |
| Retrieval relevance | Good for topically distinct documents |
Limitations Discovered
- Cold start latency: First query after Ollama restart takes longer as the model loads into memory
- Embedding speed: CPU-based embedding generation is the primary bottleneck
- Context window: With
top_k=10documents, complex queries can exceed the context window - No re-ranking: Retrieved documents are used as-is without relevance re-ranking
What I’d Do Differently
Immediate Improvements
1. Add a Re-ranking Stage
Raw vector similarity isn’t always the best relevance signal. Adding a cross-encoder re-ranker after initial retrieval would improve answer quality:
from sentence_transformers import CrossEncoder
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank_results(query, documents, top_k=5):
pairs = [(query, doc.text) for doc in documents]
scores = reranker.predict(pairs)
ranked = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
return [doc for doc, _ in ranked[:top_k]]
2. Implement Hybrid Search
Combining dense (vector) and sparse (BM25) retrieval often outperforms either alone:
# Elasticsearch supports hybrid queries natively
{
"query": {
"bool": {
"should": [
{"match": {"conversation": query_text}}, # BM25
{"knn": {"conversation_vector": {...}}} # Dense
]
}
}
}
3. Add Streaming Responses
The current implementation waits for complete generation. Streaming tokens to the UI would dramatically improve perceived latency:
# LlamaIndex supports streaming
response = query_engine.query(bundle, streaming=True)
for token in response.response_gen:
yield token
Architectural Changes
4. Separate Embedding and Generation Models
Using Llama3 for both embedding and generation isn’t optimal. Specialized embedding models (e.g., nomic-embed-text, bge-large) typically produce better retrieval results:
# Specialized embedding model
Settings.embed_model = OllamaEmbedding("nomic-embed-text")
# Larger model for generation
local_llm = Ollama(model="llama3:70b")
5. Implement Evaluation Pipeline
Without systematic evaluation, it’s impossible to measure improvements. I’d add:
- Retrieval metrics: MRR@K, NDCG
- Generation metrics: ROUGE, BERTScore against reference answers
- End-to-end: Human evaluation on a held-out test set
6. Add Centroid-based Diverse Retrieval
For long-context scenarios, retrieving semantically diverse documents prevents redundancy:
from sklearn.cluster import KMeans
def get_diverse_contexts(embeddings, k=5):
"""Cluster and return centroid-nearest documents."""
kmeans = KMeans(n_clusters=k, init='k-means++')
kmeans.fit(embeddings)
return kmeans.cluster_centers_
This addresses the “lost in the middle” problem where LLMs underweight information in the middle of long contexts.
Production Considerations
7. Add Observability
Production RAG systems need visibility into:
- Which documents were retrieved for each query
- Embedding latencies and cache hit rates
- LLM token usage and generation times
8. Implement Caching
Repeated queries should hit a cache rather than re-running the full pipeline:
from functools import lru_cache
@lru_cache(maxsize=1000)
def get_query_embedding(query_text):
return embed_model.get_query_embedding(query_text)
Key Takeaways
- Local-first RAG is viable: Ollama + Elasticsearch provides a fully private, self-hosted solution
- Chunking matters: Small chunks with overlap preserve context while enabling granular retrieval
- LlamaIndex accelerates development: The abstractions handle complexity while remaining customizable
- Evaluation is essential: Without metrics, optimization is guesswork
- Hybrid approaches win: Combining BM25 + dense retrieval + re-ranking typically outperforms any single method
Resources
Project Links
- GitHub Repository: rag-llama3-elasticsearch
- License: Apache 2.0
Technologies Used
Relevant Papers
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — Lewis et al., 2020 (Original RAG paper)
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., 2023
- Precise Zero-Shot Dense Retrieval without Relevance Labels — HyDE approach
Related Content
- Representative Centroid Selection for Long-Context RAG — A technique for diverse retrieval