Published on 2023-04-21 10:00 by Vitor Sousa
RAG with LlamaIndex, Elasticsearch and Llama3
Goal
Implement a Q&A experience utilising the Retrieval Augmented Generation (RAG) technique, with Elasticsearch as the vector database. For this implementation, we will employ LlamaIndex for indexing and retrieval, alongside a locally hosted Llama3.
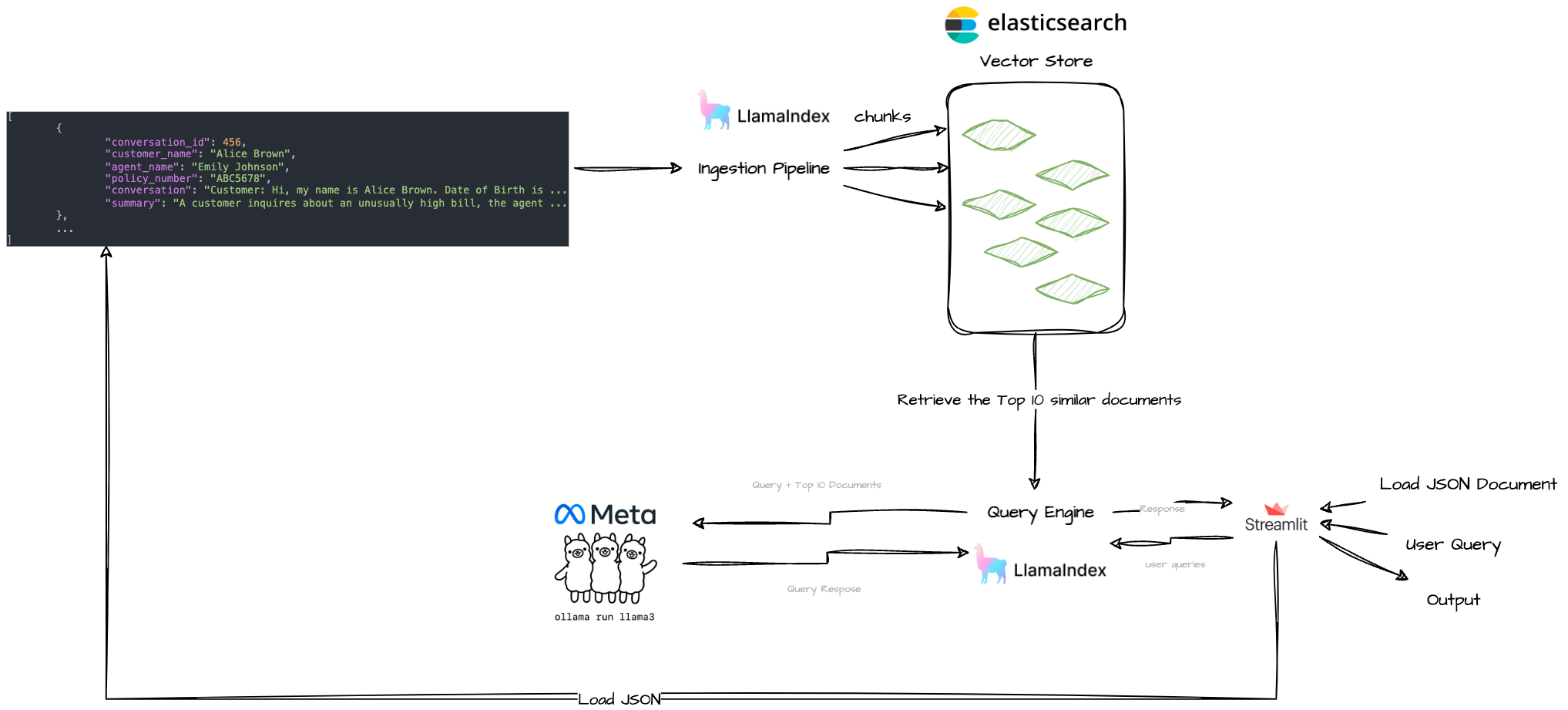
- Local Setup: We run the
llama3locally using Ollama. - Data Ingestion:
- We load the JSON file into ElasticsearchStore, a vector store backed by Elasticsearch.
- During this process, we generate embeddings with the locally running
llama3model. These embeddings, along with the actual conversation texts, are stored in the LlamaIndex Elasticsearch vector store.
- Configuration:
- We set up a LlamaIndex IngestionPipeline, integrating it with the local LLM, specifically the Mistral model via Ollama.
- Query Execution:
- When a query, such as “Give me a summary of Billing Inquiries and Corrections conversations.” is submitted, Elasticsearch performs a semantic search to fetch relevant conversations.
- These conversations, together with the original query, are fed into the locally running LLM to generate a response.
How can RAG help?
Recently, we have seen remarkable growth in Large Language Models (LLMs), and while these models have demonstrated impressive capabilities, they also come with notable challenges and limitations.
- Training LLMs is costly and time-consuming.
- These models are designed to predict the next word, making it difficult to discern how they formulate their outputs (this is known as the observability problem).
- LLMs typically rely on public datasets that ideally do not contain any private information. However, many applications, such as Q&A, summarization, and others, require personalization to tailor these models to specific datasets and problems.
- In particular, tasks that require detailed knowledge demand accurate and reliable outputs.
- Keeping LLMs current with the latest information can be challenging.
To address these issues, particularly to ensure that models utilize the most up-to-date information and tailor outputs to specific contexts or problems, and to enhance understanding of how outputs are generated, the Retrieval-Augmented Generation (RAG) technique can be employed.
RAG is a methodology that enhances large language models by integrating them with external knowledge sources, combining information retrieval and natural language generation. This integration employs a diverse range of knowledge bases including documents, databases, and websites.
Function and Applications of RAG
The primary role of the RAG function is to effectively combine the robust language comprehension abilities of extensive language models with the vast reserves of real-world knowledge found in textual data sources. This integration enables AI to deliver precise, relevant, and in-depth responses that are informed by dynamically changing external data.
Key applications of RAG include:
- Specialized question-answering services (e.g., in customer service, healthcare, and legal sectors)
- Interpreting and elucidating structured data from databases and spreadsheets
- Digital assistants capable of consulting and analyzing technical documents
- Enhancing creative writing with access to pertinent historical and contextual knowledge
- Developing AI entities capable of sustained, information-rich conversations based on the most current data
RAG under the Hood
At its essence, RAG implements a phased approach of retrieval and generation:
Data Collection & Preparation
The initial phase involves assembling the external data sources pertinent to the intended application—such as documents, databases, websites, and research papers. This unstructured data is cleaned, converted into textual format, and, if necessary, refined to enhance its quality, timeliness, and relevance to the specific domain.
In the project, I used data from a JSON file with data about customer service interactions where customers contact agents for assistance with various issues related to services, accounts, and billing.
Data Chunking
Rather than preserving entire documents as large units, RAG utilizes semantic segmentation to divide them into smaller, topic-specific sections or chunks. This segmentation facilitates more targeted retrieval during later stages, allowing the system to fetch only the most relevant sections instead of entire documents, thereby boosting both relevance and efficiency.
In the project, I used the SentenceSplitter from LlamaIndex.
Document Embeddings
Through the use of transformer-based encoders, each segmented chunk is transformed into a numerical vector that encapsulates its semantic content. These vector embeddings, which are high-dimensional, enable the system to match queries with document chunks based on conceptual similarity, moving beyond mere word-based matching.
In the project, I used the OllamaEmbedding from LlamaIndex.
Question Encoding & Retrieval
Upon receiving a query, the same model that created the document embeddings processes the query into a vector. The system then employs efficient similarity searches among these vectors to identify and retrieve document chunks that most closely align with the query based on their embeddings.
In the project, I used the OllamaEmbedding from LlamaIndex to encode the prompt.
Language Model Integration
The selected chunks of context and the initial query are combined into a prompt, which is then inputted into a large language model such as LLaMa., MISTRAL or GPT-4 The model synthesizes the provided context to generate a coherent, accurate, and current response, leveraging the external data for depth and insight.
I used the available functionalities from LlamaIndex to integrate the similar retrieved documents (top 10)and the model.
LLamaIndex
I think of LlamaIndex as a highly efficient librarian that organizes vast amounts of data from diverse sources—documents, databases, websites, and more—into a searchable format. This makes it an invaluable resource for language models, allowing them to fetch not just any information, but the exact data they need in real-time.
The Power of LlamaIndex in Enhancing RAG
- Access to the Latest Updates: LlamaIndex constantly refreshes its database, which means that it allows models to access the most current information—a crucial feature for subjects that need up-to-date insights.
- Diversity of Information: By pulling data from a myriad of sources, it provides a richer, more varied pool of information, elevating the quality of responses from the model.
- Precision in Retrieval: The true strength of LlamaIndex lies in its ability to pinpoint highly relevant information based on the query’s context, significantly boosting the accuracy and relevance of responses.
- Customization: Tailored to meet specific needs, organizations can customize LlamaIndex to index particular sources or types of data. This adaptability enhances both personalization and relevance, making the model an even more powerful tool for specific domains.
Beyond just improving existing functionalities, LlamaIndex addresses one of the most significant limitations of traditional language models—the need for continual retraining with new data. By integrating real-time and relevant data, it mitigates these constraints, thereby enhancing model performance and sustainability.
LlamaIndex, which is optimized for indexing, and retrieving data, it’s a game-changer for the application of language models, propelling them into a future where they are not only reactive but also proactive in delivering high-quality, contextual aware responses.
ElasticSearch
ElasticSearch serves as a powerful search engine that efficiently manages and organizes large datasets from various sources—including logs, transactions, social media, and other big data—into a format that’s easy to query and analyze. It’s an essential tool for developers and businesses, enhancing the capabilities of applications by providing fast, scalable search functionality.
The Impact of ElasticSearch in Enhancing Search Capabilities
- Real-Time Processing: ElasticSearch processes data in real-time, offering immediate access to the latest information. This feature is vital for applications requiring up-to-the-minute data, such as financial monitoring or social media analytics.
- Scalable Architecture: Its distributed nature allows ElasticSearch to scale horizontally, accommodating an expanding volume of data without sacrificing performance. This scalability makes it ideal for enterprises with large, growing datasets.
- Relevant Search Results: ElasticSearch excels in delivering highly relevant search results thanks to its sophisticated analysis capabilities and customizable ranking algorithms. This precision improves user experiences and application efficiency.
- Flexibility: Users can fine-tune ElasticSearch to meet specific needs by configuring its indexing properties and integrating it with various plugins and tools. This flexibility aids in tailoring search functions to specific use cases, enhancing both relevance and performance.
ElasticSearch goes beyond simply boosting search functionalities in applications. It addresses significant challenges associated with handling and searching large volumes of data efficiently. By enabling real-time data processing and offering customizable search capabilities, ElasticSearch helps businesses/products stay agile and insightful. Its role in modern data architecture is critical, as it not only facilitates immediate data retrieval but also supports complex data analysis tasks, propelling businesses towards more data-driven decision-making.
Check the repo: 🔗 RAG, Llama3, and Elasticsearch project repository.
Check the portfolio for more technical details: 👨💻 Project in My Portfolio.
This project has as reference:
“Using RAG with LlamaIndex and Elasticsearch”, Elastic Search Labs Blog, available at: https://www.elastic.co/search-labs/blog/rag-with-llamaIndex-and-elasticsearch. ↩
https://docs.llamaindex.ai/en/stable/getting_started/concepts/
https://arxiv.org/pdf/2005.11401
Written by Vitor Sousa
← Back to blog

